
From Self-QA to LLMs: Modernizing the QA Process
Introduction
Data quality is a crucial factor in achieving and building successful models. Maintaining high quality data is a challenging task as is, even more so when considering human errors during their annotation process. The manual upkeep and maintenance of these errors, and ensuring that every data batch meets its requirements after completion, can be very time-consuming. Here is when the automation of the QA process comes into play, helping reduce time and increase efficiency and effectiveness.
Annotator assistance to QA improvements
There is always a need to conduct some checks to ensure the quality of the annotations meets the requirements. However, those checks become more and more time-consuming as the data becomes larger and more complicated. Manually conducting these quality checks is not the best practice since human abilities can be limited. That being said, what if the QA process could be implemented during the annotation process, allowing for annotators to take part in and assist QAs with maintaining quality of the data?
Creating a system where annotators can also perform QA tasks on the data they’re working on, by using different tools such as Grammarly, for example, to streamline their workflow, helps to define a multilayered data labeling process that is paramount for building a good model.
Imagine a case where there is a prompt and a user is asked to provide a comprehensive answer. Even though the user is very skilled in writing, there is always a possibility of grammar mistakes, which may affect the data quality, and by extension the model's effectiveness, in the future.
Self-QA is essential as the first layer of a multilayered QA process. Ensuring responses are clear, error-free, and easy to understand lays a foundation for seamless collaboration between QA layers, creating an efficient and uninterrupted workflow.
Automated metrics generation and outlier detection
Metrics generation and outlier detection are the key things to perform QA for the tasks, especially when dealing with Large Language Models (LLMs). While building high-quality data, it’s important to understand whether the answers to the prompts are relative and do not contain outliers. Those outliers can be detected with the help of n-grams in an automated way using the Orchestrate tool.
With the help of a diversity score for each annotator, you will understand whether the provided answers contain repetitive sequences of words or they are rich and can be easily used for training purposes. Here is an example of the code that can calculate the diversity score for each annotator within a project.
import nltk
from nltk.util import ngrams
from superannotate import SAClient
sa_client = SAClient('')
# nltk.download('punkt')
# nltk.download('punkt_tab')
def ngram_diversity_score(text: str, n: int = 3) -> float:
tokens = nltk.word_tokenize(text)
n_grams_list = list(ngrams(tokens, n))
total_ngrams = len(n_grams_list)
unique_ngrams = len(set(n_grams_list))
if total_ngrams > 0:
diversity_score = unique_ngrams / total_ngrams
else:
raise ValueError("Total number of n-grams is 0.")
return diversity_score
def handler(event, context):
project_name = sa_client.get_project_by_id(context.get('project_id', -1))['name']
folder_name = sa_client.get_folder_by_id(context.get('project_id', -1), context.get('folder_id', -1))['name']
item_name = context.get('name', '')
annotation = sa_client.get_annotations(f"{project_name}/{folder_name}", [item_name])[0]
for instance in annotation['instances']:
print(instance)
if 'className' in instance and instance['className'] == 'answer':
annotator_answers = instance['attributes'][0]['name']
if 'className' in instance and instance['className'] == 'diversity_score':
id1 = annotation['instances'].index(instance)
try:
# Calculate n_gram_div_score for each annotator
# ngram size n = 3 default but can be changed here
n = 3
n_gram_div_score = f"{ngram_diversity_score(annotator_answers, n):.3f}"
# set the score in the number component and upload the annotations back to the item
annotation['instances'][id1]['attributes'][0]['name'] = n_gram_div_score
print(sa_client.upload_annotations(f"{project_name}/{folder_name}", [annotation]))
return n_gram_div_score
except ValueError as e:
raise eIt’s possible to streamline the process even more. Let’s say you want to have some sort of data on the items with their diversity score, or you want to filter the users with their average diversity score and take the respective actions. It’s more than possible and can be achieved by storing the score in the items themselves, so each item will have its own diversity score. Then with the help of the Insights tool, the user can filter annotators by their average diversity score or any other measurement connected to it.
Another example of measuring the performance of the annotators is the time spent per task. Calculating the time that an annotator spends for the completion of a single task can be used in different ways (e.g. to understand which data points are harder to annotate than the others as a form of outlier detection, or measure the average time spent by the annotator on the tasks). It will help to understand the effectiveness of the annotators and act accordingly to avoid a drop in performance.
Automated model QA: LLM-as-a-judge
Automation of the QA process can be done using LLMs and considering them as a judge. In a simple example where the annotator needs to write a caption based on a given image and an autogenerated caption. Instead of using manual QA for the written caption, we can engage models to do that for us.
First, we can feed the model a short rubric with the instructions on what should be considered, then we can feed the human-generated caption alongside the autogenerated caption and ask the model to write a response, including a rating, reasoning, and action items.
This approach to the automation of the QA process will enable the annotator to receive direct feedback by just clicking on a button while working on the task and continuously improve it until it reaches an acceptable level of accuracy.
from typing import List, Union
import requests
import sa
import requests.asyncs as requests
from environments import openai_token, url
import json
# Define the rubric variable
rubric = """
A user are given an autogenerated caption to an image. The user then examines carefully unique details of the image, and improves on this caption, keeping and/or removing as much as needed. the basis on which the user improves the image should be done with high-level descriptions first, and then narrow in on details as follows:
- Remove any information that is incorrect or irrelevant from the starter caption.
- Make sure that the caption makes no assumptions. I.e. if a drink looks like a mojito, it must say it “looks like a mojito” not “it is a mojito”.
- Change wording, information, and details when appropriate to give more depth to the caption.
- Add new information to the caption that is missing.
- Change the ordering of the text if it does not make sense.
- Rewrite the caption entirely when necessary.
"""
TEMPLATE = """
Your task is to assess the input text based on the rubric provided below. First, determine whether the input text meets or does not meet the rubric's criteria. Then, explain your reasoning in a few concise bullets. Then, give actions items in a few concise bullets to fix it. All of the characters in the response must be less than 2048 characters, mandatory.
Rubric:
{rubric} All of the characters in the response must be less than 2048 characters, mandatory.
Output format:
- Result: Pass/Fail or Meets rubric/Does not meet rubric
- Reasoning: Bullet points highlighting the reason for the result
- Action Item: Bullet points highlighting what to fix
Autogenerated text: "{auto_text}"
Revised text: "{revised_text}"
"""
textarea_caption = ['caption']
image_image_link = ['image_link']
button_llm_autocheck = ['llm_autocheck']
paragraph_auto_caption = ['auto_caption']
textarea_ai_eval_text = ['ai_eval_text']
async def on_llm_autocheck_click(path: List[Union[str, int]]):
### Start loading
sa.setLoading(True)
### Get values
old_caption = sa.getValue(paragraph_auto_caption)
new_caption = sa.getValue(textarea_caption)
### Format the template with the rubric and caption
formatted_message = TEMPLATE.format(rubric=rubric, auto_text=old_caption,revised_text=new_caption)
### Request eval
completionOpenAi = await openAiCompletion(formatted_message)
### Set the completion values in the UI
sa.setValue(textarea_ai_eval_text, completionOpenAi)
### Remove the loading
sa.setLoading(False)
return
async def openAiCompletion(message: str):
### Create OpenAI request body
questionBody = {
"model": "gpt-4-turbo",
"messages": [{"role": "user", "content": message}]
}
### Create OpenAI headers object
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {openai_token}"
}
### Send the request
fetchedValue = await requests.post(
url="https://api.openai.com/v1/chat/completions",
json=questionBody,
headers=headers
)
### Parse the response
res = fetchedValue.json()
### Get the completion
answer = res["choices"][0]["message"]["content"]
return answerThe example Python code above shows how to interact with the model API, how to feed the rubric written and predefined captions, and receive the response from it. It can be integrated directly into the setup of the platform’s Multimodal editor. From the user's perspective, the result of an LLM judge QA process will look like the image below:
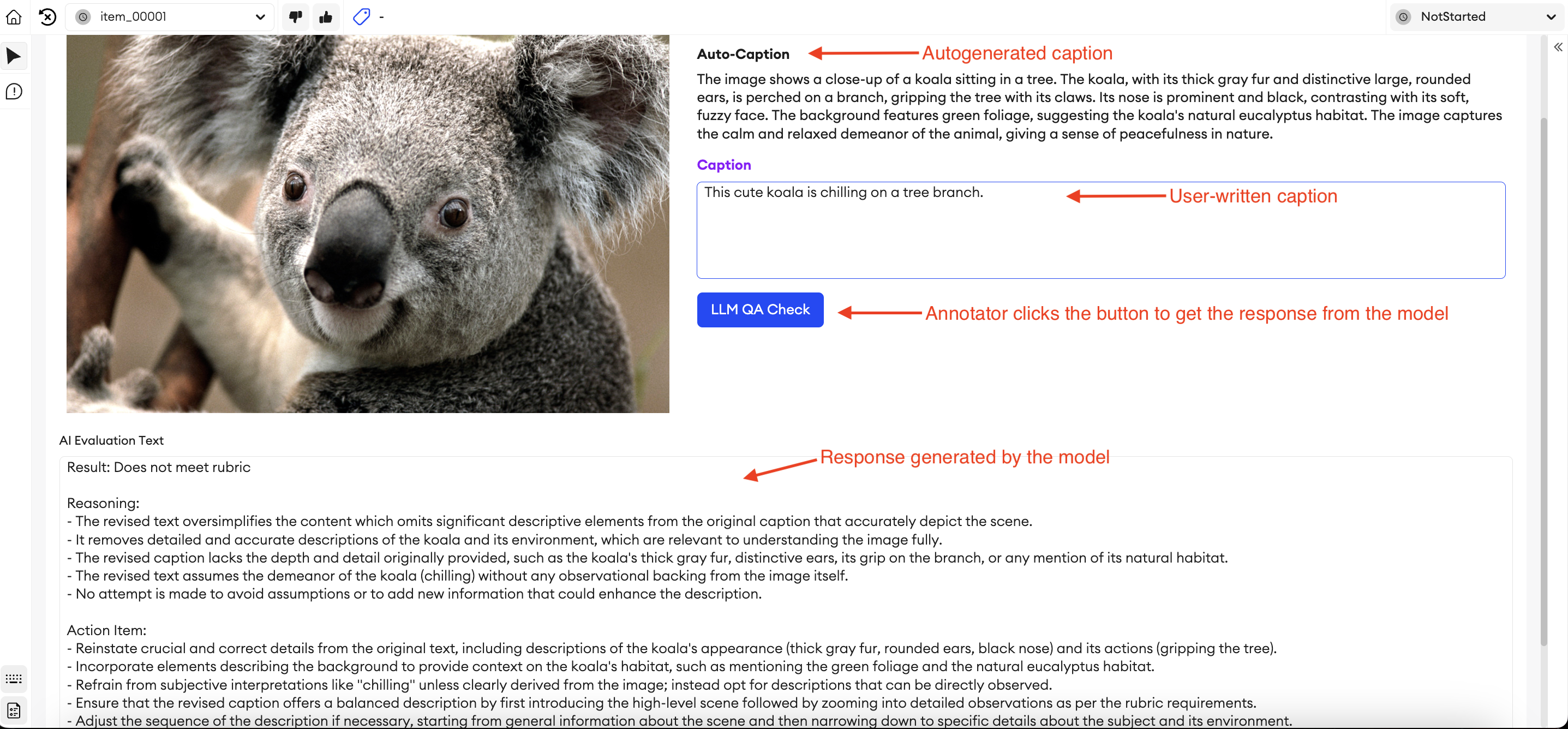
Judging through LLMs can be organized like a scoring model as well, where the LLM analyzes and provides a score based on predefined metrics. This approach is different from the previous one since in this case, the LLM only grades the answers, but it doesn’t explain how to improve them or what the reason was for a high or low score.
From the use case perspective, the scoring approach is much better to use on tasks where you need to eliminate incorrect data without doing much rework or when you want to add another layer of the QA. For example, when there is already a layer where a manual QA process is involved with the human scorer.
The first layer eliminates the unnecessary data and only leaves the ones that are acceptable for the model training. Then we use the LLM judge scoring model to filter out even more data, increasing the quality and removing outliers. Below is a simple code example for the scoring approach.
import openai
import re
# Set up your OpenAI API key
openai.api_key = ""
class GPTJudge:
def __init__(self):
self.model = "gpt-4" # Choose the model to use (e.g., gpt-4)
def evaluate(self, question, answer):
# Construct the prompt for evaluation
prompt = f"""
You are a professional evaluator tasked with scoring answers based on three criteria:
- Grammar (How correct and fluent the grammar is).
- Relevance (How well the answer directly addresses the question).
- Politeness (How respectful and non-offensive the tone is).
For each criterion, give a score between 0 and 1 (0 = worst, 1 = best) and then only provide the overall score without explanations.
Question: {question}
Answer: {answer}
Provide the scores and explanations in the following format:
Overall score: <score>
"""
# Query GPT to evaluate the response
response = openai.ChatCompletion.create(
model=self.model,
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}]
)
pattern = r"(?<=: )[^:]*$"
evaluation = re.search(pattern, response['choices'][0]['message']['content'], re.DOTALL)
return evaluation.group()
# Example usage
judge = GPTJudge()
question = "What book did you find?"
answer = ("I was excited to find a book ostensibly about Muslim feminism, "
"but this volume did not live up to the expectations. One essay, "
"among other things, describes the veil as potentially liberating. "
"It doesn't begin to explain how or why. Another, on Muslim women in Cape Town, "
"claims that Muslim women there are separate but 'more than equal.' "
"Gee whiz, what a disappointment. I had expected and hoped for at least one "
"Muslim feminist condemnation of gender apartheid. But there is not a single one in the book. "
"I'm surprised it didn't have an essay extolling the virtues of female genital mutilation.")
evaluation = judge.evaluate(question, answer)
print(evaluation)Another option is using the reward models that are specifically designed to give the scores to the prompts and answers as a whole based on a couple of attributes. One of those models is Nvidia’s Nemotron-4 340. It analyses the conversation and provides rewards for its helpfulness, correctness, coherence, complexity, and verbosity independently. This approach leads to more nuanced evaluations and helps identify specific strengths or weaknesses in responses.
The Python script below demonstrates the interaction between the reward model and the question-response pair from the platform. It returns the scores of the attributes from 0 to 4 range.
import os
from openai import AsyncOpenAI
import asyncio
import nest_asyncio
def get_scores_from_response(openai_response_template):
logprobs = openai_response_template.choices[0].logprobs.content
score_dict = {}
for score in logprobs:
score_dict[score.token] = score.logprob
return score_dict
async def get_response_and_scores(client, model, question, response_content):
messages = [
{
"role": "user",
"content": question
},
{
"role": "assistant",
"content": response_content
},
]
response = await client.chat.completions.create(
model=model,
messages=messages,
)
scores = get_scores_from_response(response)
return scores
async def process_question_response_pairs(client, model, question_response_score_list):
tasks = []
for question_response_pair in question_response_score_list:
question = question_response_pair["question"]
task_a = get_response_and_scores(client, model, question,
question_response_pair["responses"]["response_a"]["response"])
tasks.append((task_a, question_response_pair, "response_a"))
results = await asyncio.gather(*[task[0] for task in tasks])
for i, (result, task_info) in enumerate(zip(results, tasks)):
_, question_response_pair, response_key = task_info
question_response_pair["responses"][response_key].update(result)
def handler(event, context):
return asyncio.run(async_handler(event, context))
async def async_handler(event, context):
client = AsyncOpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key="Your_key"
)
nest_asyncio.apply()
question_response_pair_list = [{
"question": context['question'],
"responses": {
"response_a": {"response": context['responses']}
},
}]
question_response_score_list = question_response_pair_list.copy()
print(question_response_score_list)
await process_question_response_pairs(client, "nvidia/nemotron-4-340b-reward", question_response_score_list)
return [item for item in question_response_score_list]Create a custom action in Orchestrate with the above script and respective dependencies, then bind it to the Incoming webhook event. This will create a flow that triggers the action whenever it is called through the webhook.
The snippet below shows how to trigger an action from the item itself by clicking a button and updating the scores in their respective components. It should be included in the Multimodal project's code editor, with the actual webhook URL (remember to add /result after the URL) and its API from the Incoming Webhook event set up earlier.
async def on_reward_click(path: List[Union[str, int]]):
webhook_url = "actual_webhook_url/result"
# Define the API key
headers = {
"API-key": ""
}
payload = {
'question': sa.getValue(markdown_question),
'responses': sa.getValue(markdown_response)
}
response = requests.post(webhook_url, json=payload, headers=headers)
try:
response_data = response.json()
print("Response JSON:", response_data)
result = json.loads(response_data['output'])
sa.setValue(number_helpfulness, result[0]['responses']['response_a']['helpfulness'])
sa.setValue(number_correctness, result[0]['responses']['response_a']['correctness'])
sa.setValue(number_coherence, result[0]['responses']['response_a']['coherence'])
sa.setValue(number_complexity, result[0]['responses']['response_a']['complexity'])
sa.setValue(number_verbosity, result[0]['responses']['response_a']['verbosity'])
except ValueError:
print("Response Text:", response.text)Closing Notes
In the evolving data annotation landscape, Quality Assurance is a critical pillar for ensuring accuracy, reliability, and scalability. The journey from self-QA to the integration of advanced tools like LLMs demonstrates the transformative potential of technology in modernizing QA processes.
By combining human expertise with automated systems, organizations can achieve unparalleled levels of efficiency while maintaining the integrity of annotated datasets. The use of LLMs as judges, coupled with robust metrics and layered QA mechanisms, provides a scalable framework for handling complex annotation challenges. Together, these advancements not only streamline the QA process but also pave the way for future breakthroughs in AI-driven data workflows.
Updated 2 months ago