
Templates
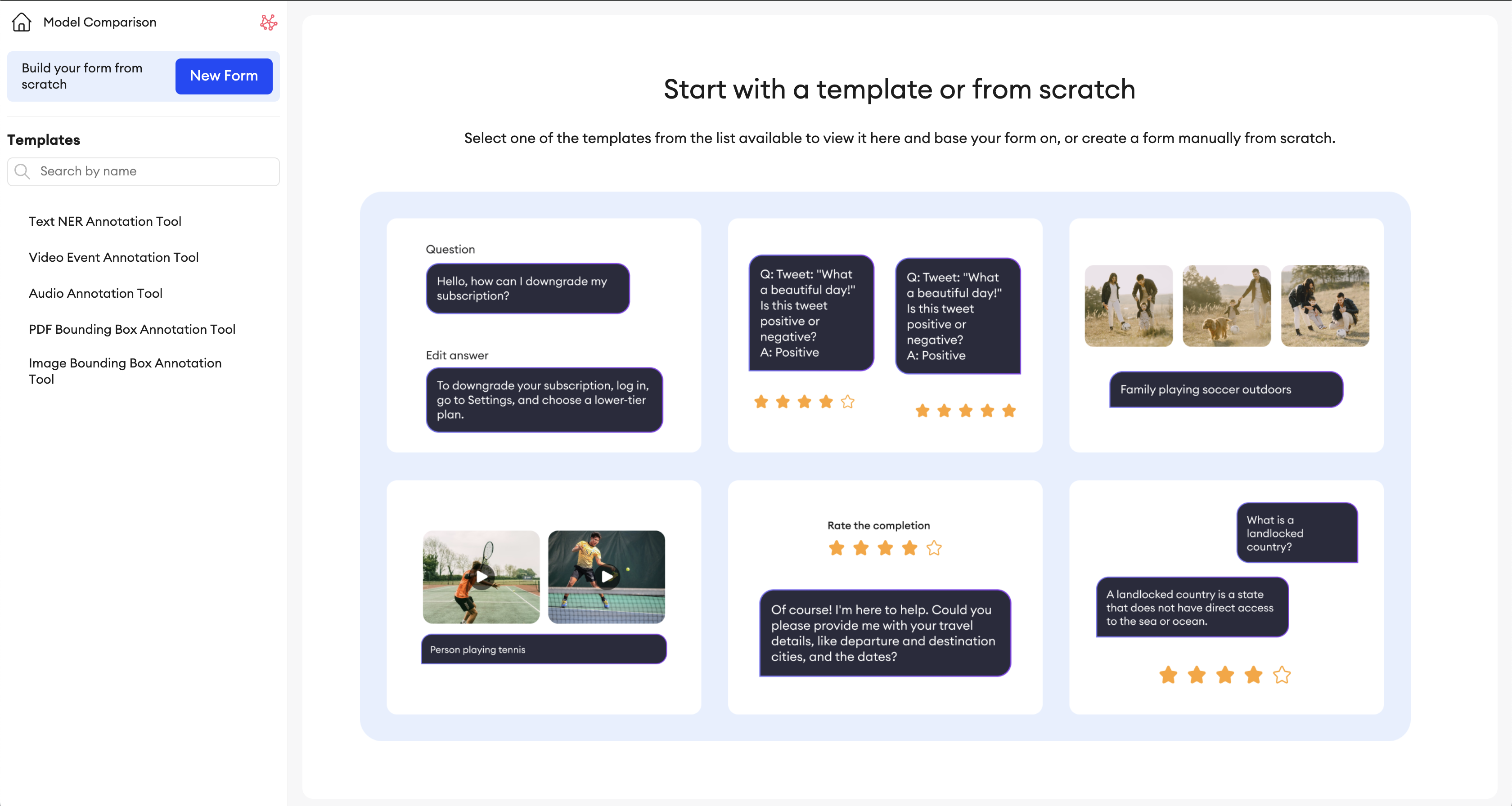
Multimodal projects are very versatile and can be used to fulfill a number of various use cases. When creating your project, you can either build a form from scratch or select from a number of available templates.
Choosing a template
In the templates page, you'll find a list of Multimodal form templates to choose from in the left panel.
By clicking one, you'll see a preview of it and how it will look, as well as any pre-written functionality it might have.
README
In the top right corner of the page, you can click the README button to view the details and key information written about each template.
Creating a form manually
If you would rather build your form from scratch rather than start with a template, simply click New Form in the top left corner.
Use Cases
You'll find a few listed examples below that you can check out to see what this builder can be used for. These templates can be downloaded so that you can try them out in your own projects. You can also test them out for free in the Multimodal Playground on our website.
Updated about 1 year ago
Did this page help you?