
QA automation
Introduction
Data quality is crucial for a successful model and might be the most important step in achieving it. However, maintaining high data quality is challenging due to human errors during the annotation process. Manually checking for these errors, correcting them, and ensuring the batch meets requirements after completion, can be very time-consuming.
This is where SuperAnnotate’s Orchestrate feature comes in. It’s a way to automate certain tasks within your ML pipeline which can create processes that take place automatically without any additional prompt. For example, it automates dataset validation and quality assurance, identifying errors and providing direct feedback to the annotators, thus streamlining the process.
When to automate QA
The QA process is essential to ensure high data quality before using it to train a model. Automating this process can make data delivery faster and more efficient, especially with the Orchestrate where an automated QA process is integrated into the annotation workflow to make the corrections directly without additional steps. However, depending on the use case, setup, or data specifications, a programmatic approach to QA automation may not always be feasible. Automation can't determine whether an annotation covers the entire object, only part of it, or includes parts of other objects without visually looking into it. However, it can be used to check if an instance overlaps with other instances. Therefore it’s important to understand when automation is appropriate.
The setup of the project can be the starting point to identify the possible areas where automation can be implemented:
- Multimodal - automated QA can be used to check the number of words in the answers to meet the requirements set in the project instructions. For example, the number of words in an answer can affect the model’s effectiveness. This necessitates dataset validation, which is much easier with QA automation, as manually checking all the answers would be very time-consuming.
- Images - automated QA can be used to identify the size of the instances and delete the ones with more or less than the given number of pixels.
- Videos - automated QA can be used to check the blank attributes of the classes and fill them with necessary ones.
- Text - automated QA can be used to check whether the user uses all the items of the same data for the classification task or not.
What to think about
When creating an automated QA pipeline or writing a script that should be triggered upon a specific event trigger, it’s highly recommended to understand how the processes work on the platform.
The Orchestrate feature allows users to host scripts that get the annotations and perform necessary checks and corrections. Orchestrate allows users to set up a custom response sequence using Custom actions, which can be bound to specific event triggers in the pipeline. This means that the event selected, be it a folder’s status change or an item’s completion, can trigger the customized action to commence and carry out its order. These can be created in the Actions tab.
The first thing to consider is which event suits your project’s needs the most. If the custom action is checking a large number of items simultaneously, it’s highly recommended to choose a project-level or folder-level event. This will greatly reduce the runtime of the automation.
If the user wants to check several items without affecting the rest of the data, an item-level event should be selected. The common practice is to use item-level events since the annotators get feedback almost in real-time, which also speeds up the rework process, cutting down the wait time.
The next thing to consider is how to address any errors identified by an automated QA check. There are several methods to handle this. If the item contains an instance that doesn’t meet the requirements, it can be disapproved, or deleted, or the user can programmatically add a comment to flag the instance for annotators to review, which is the more common practice. This is because comments are customizable; the user can point out whatever they want, make suggestions, and instruct the annotator specifically. The items with these errors can be returned to the annotator for corrections.
Items have different statuses, as you can see here. Each status indicates a different step of the QA workflow that the item can pass. When an item doesn't pass the automated check, the status of the item can be changed to Returned automatically (or any other status as per the need). This allows the user to easily filter out the items with the specified status and make corrections on them.
How to implement
To implement a custom action, Python is used to write the script that dictates the functionality. With custom actions, a handler function receives the event and context attributes by default. The event attribute contains general information about the event itself and some user-imputed custom variables that can be added from the Pipelines section, while the context attribute contains information about the item: its name, project ID, folder ID, and a bit of information before the change and after the change, which can be used in the script. For example, the Item annotation status update event provides a context that looks like this:
{
"op": "u",
"before": {
"id": 41158539,
"name": "test.jpeg",
"qa_id": null,
"qa_name": null,
"team_id": 19744,
"createdAt": 1675075465000,
"folder_id": 309326,
"is_pinned": false,
"source_id": "4792bc5e-9ad6-4f04-85d9-2fcd63c088d1",
"updatedAt": 1675075465000,
"project_id": 122101,
"annotator_id": null,
"entropy_value": null,
"annotator_name": null,
"approval_status": null,
"annotation_status": "NotStarted",
},
"after": {
"id": 41158539,
"name": "test.jpeg",
"qa_id": null,
"qa_name": null,
"team_id": 19744,
"createdAt": 1675075465000,
"folder_id": 309326,
"is_pinned": false,
"source_id": "4792bc5e-9ad6-4f04-85d9-2fcd63c088d1",
"updatedAt": 1675075467000,
"project_id": 122101,
"annotator_id": null,
"entropy_value": null,
"annotator_name": null,
"approval_status": null,
"annotation_status": "InProgress",
},
"ts_ms": 1675075467014,
}To host the script in the custom action, first click on + New Action in the Actions tab under the Orchestrate feature. Then you can either create a new action and paste your script there, or import it from Github where your script is hosted, or use one of the templates already available on the platform.
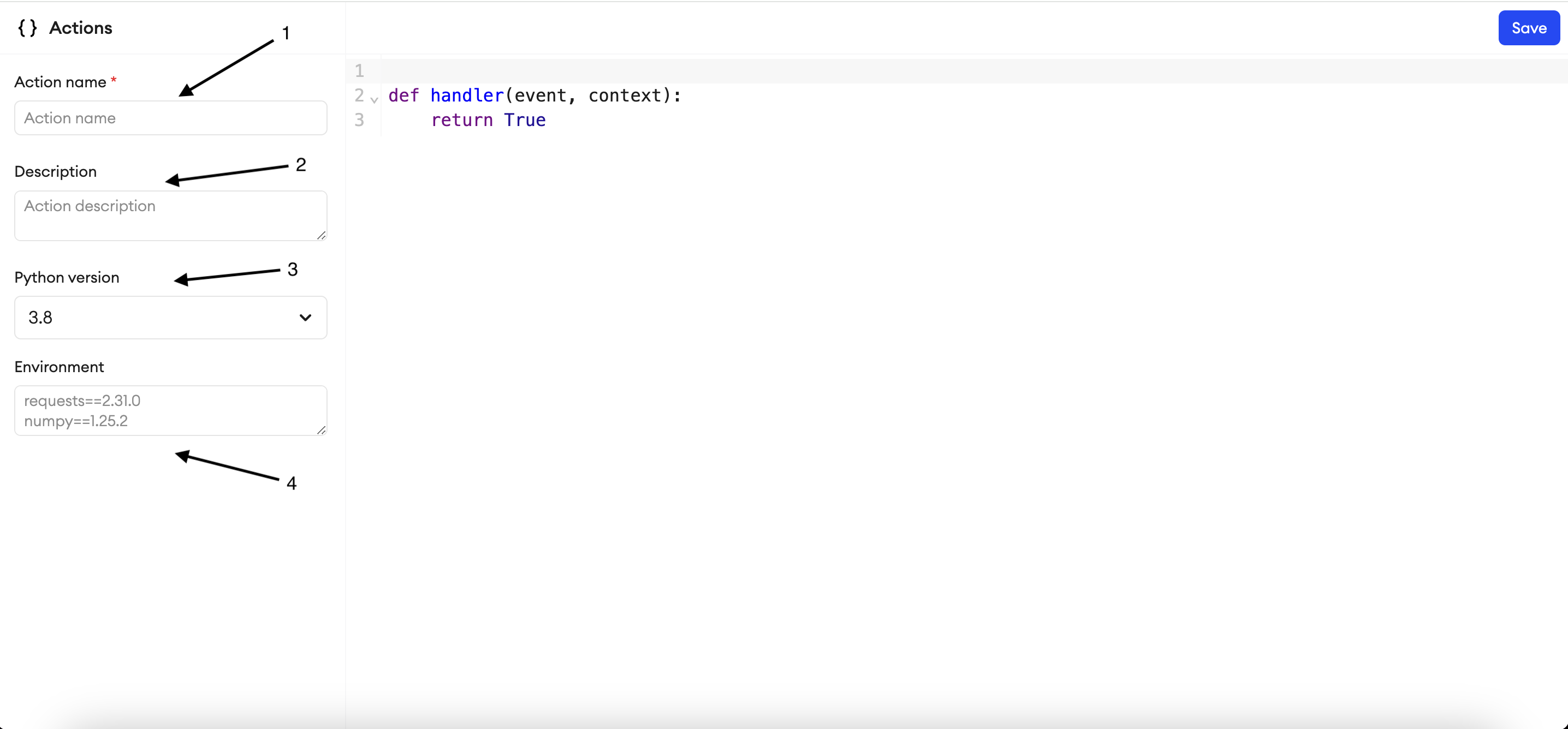
- Add a name for the custom action.
- Write a description for the action (optional).
- Choose a Python version on which you want the script to run.
- Provide the required libraries to use in the code, like
superannotatefor the SuperAnnotate SDK, and click Save.
The second step is to create a pipeline and make use of your custom action.
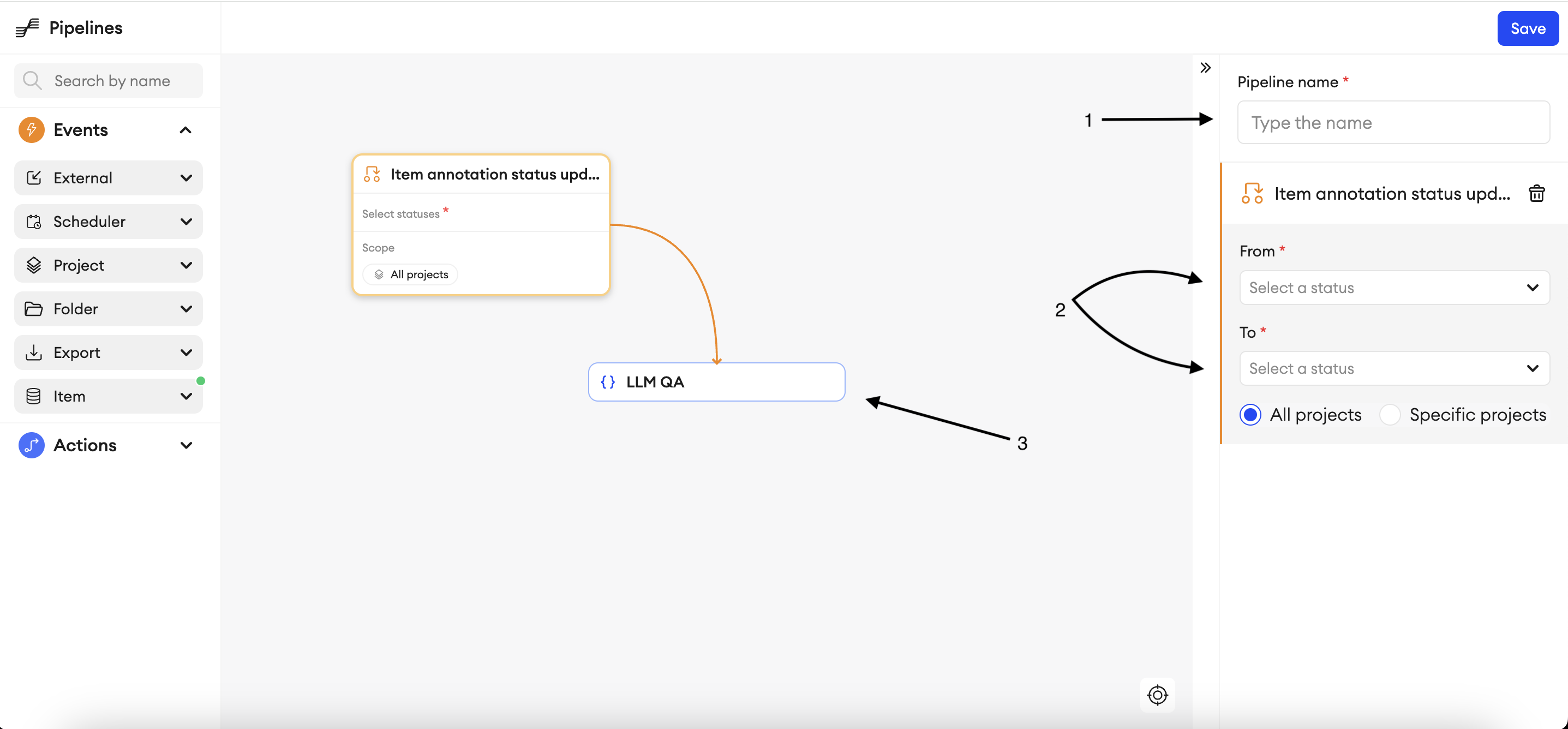
- Add a name for the pipeline.
- Choose the status updates for which you want the event to be triggered.
- Link the event to your custom action and click Save.
How our formats work
Image Project
The annotation JSON in Image projects contains four main fields: metadata, instances, tags, and comments.
Metadata gives general information about the item itself, Instances contain the list of annotations itself, Tags are for the free text tags, and Comments contain the comments that the item has on it.
Comments
Comments is a list of dictionaries, where each dictionary is a separate comment.
[{
"correspondence": [
{
"text": "Fix this",
"email": "[email protected]"
}
],
"x": 987.98,
"y": 722.87,
"resolved": false
}]Description:
- "correspondence": array of objects - List of messages in the comment.
- "text": string - The comment.
- "email": string - The email address of the user who wrote the comment.
- “x”: number - X position of the comment on the image.
- “y”: number - Y position of the comment on the image.
- “resolved”: boolean - If it’s
true, then the comment is resolved. If it’sfalse, then the comment isn't resolved.
Instances
Instances contain the annotations themselves. Below is an example of how the polygon’s annotation looks in the JSON.
{
"type": "polygon",
"className":"pentagon",
"probability": 100,
"points": [
322.18,
249.03,
585.14,
261.22,
377.9,
449.31,
243.81,
410.99
],
"groupId": 0,
"attributes": [
{
"name":"Green",
"groupName":"Color"
}
],
"error": null
}Description:
- “type”: string - Instance type.
- "className": string - Class name (one of the class names in “classes.json”, or an empty value if the instance is not classified).
- “points”: array of objects - Points of the polygon. The list of floats is: [x0, y0, x1, y1, ….. xN, yN].
- “attributes”: array of objects - List of attributes for this polygon.
- "name": string - Attribute name
- "groupName": string - Group name
- “error”: boolean - If the instance is approved, then it’s
false. If it’s disapproved, then it’strue. If you approve or disapprove of an instance and then undo the action, then it’snull. If the instance is neither approved nor disapproved, then the error won’t appear in JSON.
With the automated QA, our goal is to check the area of the polygon to see if it lies outside the given number of pixels. If so, the automation should disapprove the item, and add comments accordingly. So, when checking it, make sure to change the value of the error key to true, and when adding a comment make sure to write a comment text and make the value of the resolved key false.
A more detailed description of the JSON format for Images can be found here.
Video or Audio Project
The annotation JSON in Video or Audio projects contain three main fields: metadata, instances, and tags.
Unlike with the Image projects, in the Video or Audio projects, comments are also considered as instances, so the following formats should be used in the automation QA script to have a proper functioning workflow.
Comments
{
"meta": {
"type": "comment",
"resolved": false,
"start": 0,
"end": 7000
"correspondence": [
{
"text": "Fix this",
"email": "[email protected]",
}
]
},
"parameters": [
{
"start": 0,
"end": 7000,
"timestamps": [
{
"timestamp": 0,
"points": {
"x1": 10,
"x2": 10,
"y1": 10,
"y2": 20
}
},
{
"timestamp": 7000,
"points": {
"x1": 10,
"x2": 10,
"y1": 20,
"y2": 20
}
}
]
}
]
}Description:
- “meta”: objects
- “type”: string - The dictionary is a comment.
- “resolved”: boolean - If it’s
true, then the comment is resolved. If it’sfalse, then the comment isn't resolved. When you upload a comment, the default value isfalse. - “start”: integer - The time that marks the beginning of the comment. The timestamp is in microseconds.
- “end”: integer - The time that marks the end of the comment. The timestamp is in microseconds.
- "correspondence": array of objects - List of messages in the comment.
- "text": string - The comment.
- "email": string - The email address of the user who wrote the comment.
- “parameters”: array
- “start”: integer - The time that marks the beginning of a comment. The timestamp is in microseconds.
- “end”: integer - The time that marks the end of a comment. The timestamp is in microseconds.
- “timestamps”: array - Shows information about a comment at specific timestamps (start, end, edit).
- “timestamp”: integer - Timestamp that marks the change of the comment. The timestamp is in microseconds.
- “points”: objects - Points of the comment in this location on the timeline. The list of floats is: "x1, y1" for the left upper corner and "x2, y2" for the lower right corner.
The mentioned fields are mandatory for comments.
Bounding box
[{
"meta": {
"type": "bbox",
"className": "Class 1",
"start": 0,
"end": 10617971
},
"parameters": [
{
"start": 0,
"end": 10617971,
"timestamps": [
{
"points": {
"x1": 515.51,
"y1": 216.7,
"x2": 866.79,
"y2": 678.58
},
"timestamp": 0,
"attributes": []
},
{
"points": {
"x1": 515.51,
"y1": 216.7,
"x2": 866.79,
"y2": 678.58
},
"timestamp": 10617971,
"attributes": [
{
"name": "Attribute1",
"groupName": "Group 1"
}
]
}]
}]
}
]Description:
- “meta”: objects
- “type”: string - The dictionary is a Bounding Box.
- "className": string - Class name (one of the class names in “classes.json”, or an empty value if the instance is not classified).
- “start”: integer - The time that marks the beginning of a bounding box. The timestamp is in microseconds.
- “end”: integer - The time that marks the end of a bounding box. The timestamp is in microseconds.
- “parameters”: array
- “start”: integer - The time that marks the beginning of a bounding box. The timestamp is in microseconds.
- “end”: integer - The time that marks the end of a bounding box. The timestamp is in microseconds.
- “timestamps”: array - Shows information about a bounding box at specific timestamps (start, end, edit).
- “timestamp”: integer - Timestamp that marks the change of the bounding box. The timestamp is in microseconds.
- “points”: objects - Points of the bounding box in this location on the timeline. The list of floats is: "x1, y1" for the left upper corner, and "x2, y2" for the lower right corner.
- “attributes”: array - List of attributes for the bounding box, in this location on a timeline.
- "name": string - Attribute name
- "groupName": string - Attributes group name
With the automated QA, our goal is to check whether the class has mandatory attributes, and if those attributes have been filled in. And if they haven’t, we need to add a comment on the frames where the attribute should be filled. So, when doing this, make sure to add a comment as an instance with typed up feedback text denoting the missing attribute field, and pass that text as well as the comment’s timestamps, which should be visible on the comment in the editor.
A more detailed description of the JSON format for Videos can be found here.
Text project
The annotation JSON in Text projects contain four main fields: metadata, instances, tags, and freeText. The instance types in Text projects are Entities or Tags. However, like in the Video projects, comments are also considered as instances.
Entity
[
{
"type": "entity",
"className": "Spam",
"start": 562,
"end": 634,
"attributes": [
{
"name": "first",
"groupName": "Type"
}
]
}
]Description:
- “type”: string - Instance type. If it’s an entity, then the instance is an annotation. If it’s a tag, then the instance is a tag.
- “className”: string - Class name (one of the class names in “classes.json”).
- “start”: number - The index of the instance’s first character. The index of the first character is 0.
- “end”: number - The index of the instance’s last character.
- “attributes”: array of objects - List of attributes for the instance.
- "name": string - Attribute name
- "groupName": string - Attribute group name
Tags
[
{
"type": "tag",
"className": "Spam",
"attributes": [
{
"name": "first",
"groupName": "Type"
}
]
}
]Description:
- “type”: string - Instance type. If it’s an entity, then the instance is an annotation. If it’s a tag, then the instance is a tag.
- “className”: string - Class name (one of the class names in “classes.json”).
- “attributes”: array of objects - List of attributes for the instance.
- "name": string - Attribute name
- "groupName": string - Attribute group name
Comments
[{
"type": "comment",
"start": 200,
"end": 209,
"resolved": false,
"correspondence": [
{
"text": "comment",
"email": "[email protected]"
}
]
}]Description:
- “type”: string - The dictionary is a comment.
- “start”: number - The index of the instance’s first character. The index of the first character is 0.
- “end”: number - The index of the instance’s last character.
- “resolved”: boolean - If it’s
true, then the comment is resolved. If it’sfalse, then the comment isn't resolved. When you upload a comment, the default value isfalse. - "correspondence": array of objects - List of messages in the comment.
- "text": string - The comment.
- "email": string - The email address of the user who wrote the comment.
With the automated QA, our goal is to check whether the item has been annotated according to the classification task or not. So, when checking it, we need to identify whether all the instance types are Entities or Tags, and if not, make sure to add a comment as an instance with typed-up feedback text denoting the instance type, and pass the text of the comment as well as start and end dates which can be found on the comment in the editor.
A more detailed description of the JSON format for Texts can be found here.
Multimodal project
The annotation JSON in Multimodal project contains two main fields: metadata, and instances (including comments). There are various types of instances in Multimodal projects, depending on each instance’s component type. It can be a Media component (PDF, Video, Web, etc), an Input component (Text input, Number, Code, etc), and so on.
Instances
{
"type": "number",
"attributes": [
{
"name": 1,
"groupName": "value_r_hordi8"
}
],
"element_path": [
"r_hordi8"
],
"className": "r_hordi8"
}Description:
- “type”: string - Instance type.
- “className”: string - Class name.
- “attributes”: array of objects - List of attributes for the instance.
- "name": string or float - Value of the component
- "groupName": string - Component id
- “element_path”: list - Path of the component in the builder, if it’s in another component like Group, the list contains the component ids of parent components
Comments
[{
"type": "comment",
"referenceId": "a17f2db0-0070-4595-b4b7-5677fa84326f"
"resolved": false,
"correspondence": [
{
"text": "comment",
"email": "[email protected]"
}
]
}]Description:
- “type”: string - The dictionary is a comment.
- “resolved”: boolean - If it’s
true, then the comment is resolved. If it’sfalse, then the comment isn't resolved. When you upload a comment, the default value isfalse. - "correspondence": array of objects - List of messages in the comment.
- "text": string - The comment.
- "email": string - The email address of the user who wrote the comment.
- “type”: string - The dictionary is a comment.
- “referenceId”: string - Instance ID of the component to which the comment is referencing
- “resolved”: boolean - If it’s
true, then the comment is resolved. If it’sfalse, then the comment isn't resolved. When you upload a comment, the default value isfalse. - "correspondence": array of objects - List of messages in the comment.
- "text": string - The comment.
- "email": string - The email address of the user who wrote the comment.
Since the Multimodal editor is super customizable, several components such as Text Inputs or Text Areas can be used to host any feedback, in alternative to the Comments.
A more detailed description of the components and instances can be found here.
Examples for Image, Video, Text, and Multimodal
Image Project
Here is an automated script example that receives an event trigger from the platform when the automations are done and the items are marked as Completed. The automated QA script gets the annotations and checks for polygons with an area of less than 30 pixels. If it finds any, the automation disapproves the given instance and uploads the annotations back to the platform with the changes made.
from superannotate import SAClient
from shapely.geometry import Polygon
import numpy as np
from copy import deepcopy
# initialize
sa_token = os.environ.get("SA_TOKEN")
sa_client = SAClient(token=sa_token)
def handler(event, context):
# get the project name, folder name and item name
item_name = context['after']['name']
project_name = sa_client.get_project_by_id(context['after']['project_id'])['name']
folder_name = sa_client.get_folder_by_id(context['after']['project_id'], context['after']['folder_id'])['name']
# check if the item is from the specific folder or from the root folder
if folder_name == 'root':
item_path = project_name
else:
item_path = f"{project_name}/{folder_name}"
# get the annotations
anns = sa_client.get_annotations(project=item_path, items=[item_name])
annotations = []
# check if the area of the polygon is less than 30 pixels and disapprove the instance
for ann in anns:
error = False
for i in range(len(deepcopy(ann['instances']))):
if ann['instances'][i]['type'] == 'polygon':
points = ann['instances'][i]['points'].copy()
pts = np.reshape(points, [-1, 2])
polygon = Polygon(pts)
if polygon.area < 30:
ann['instances'][i]['error'] = True
error = True
if error:
annotations.append(ann)
# upload changed annotations and set the status of the item to Returned
if len(annotations) > 0:
print(sa_client.upload_annotations(project=item_path, annotations=annotations, keep_status=True))
sa_client.set_annotation_statuses(item_path, "Returned", [item_name])Video Project
Here is an automated script example that receives an event trigger from the platform when the automations are done and the items are marked as Completed. The automated QA script gets the annotations and checks for any bounding boxes with missing attributes. If the requirement is satisfied, the automation adds a comment to the instance and uploads the annotations back to the platform with the changes made.
from superannotate import SAClient
import os
# initialize
sa_token = os.environ.get("SA_TOKEN")
sa_client = SAClient(token=sa_token)
# create a comment
def add_comments(start, end, points_start, points_end):
comment = {
"meta": {
"type": "comment",
"start": start,
"end": end,
"correspondence": [
{
"email": "[email protected]",
"text": "The attribute is missing for this bbox. Please add it."
}
],
"resolved": False
},
"parameters": [
{
"start": start,
"end": end,
"timestamps": [
{
"points": points_start,
"timestamp": start
},
{
"points": points_end,
"timestamp": end
}
]
}
]
}
return comment
def handler(event, context):
# get the project name, folder name and item name
current_state = context['after']
video_name = current_state['name']
project_id, folder_id = current_state['project_id'], current_state['folder_id']
project_name = sa_client.get_project_by_id(project_id)['name']
folder_name = sa_client.get_folder_by_id(project_id, folder_id)['name']
# check if the item is from the specific folder or from the root folder
if folder_name == "root":
item_path = project_name
else:
item_path = f"{project_name}/{folder_name}"
upload = False
# get the annotations
annotations = sa_client.get_annotations(item_path, [video_name])
# check the bounding box instances and find the ones with missing attributes
for annotation in annotations:
for instance in annotation['instances']:
if instance['emta']['type'] == 'bbox':
for j in range(len(instance['parameters'])):
start = instance['parameters'][j]['start']
end = instance['parameters'][j]['end']
for k in range(len(instance['parameters'][j]['timestamps'])):
if instance['parameters'][j]['timestamps'][k]['attributes']:
continue
if instance['parameters'][j]['timestamps'][k]['timestamp'] == start:
points_start = instance['parameters'][j]['timestamps'][k]['points']
elif instance['parameters'][j]['timestamps'][k]['timestamp'] == end:
points_end = instance['parameters'][j]['timestamps'][k]['points']
comment = add_comments(start, end, points_start, points_end)
annotation['instances'].append(comment)
upload = True
# upload the annotations with comments back to the platform
if upload:
print(sa_client.upload_annotations(item_path, annotations=annotations))Text Project
Here is an automated script example that receives an event trigger from the platform when the automations are done and the items are marked as Completed. The automated QA script gets the annotations and checks the instance types. If there is more than one instance type, the automation uploads the annotations of one instance type back or, if needed, it leaves a comment on the instance first and then uploads the annotations with the changes made.
from superannotate import SAClient
import os
# initialize
sa_token = os.environ.get("SA_TOKEN")
sa_client = SAClient(token=sa_token)
# create a comment
def add_comments():
body = {
"type": "comment",
"start": 100,
"end": 110,
"resolved": False,
"correspondence": [
{
"text": "The annotations are incorrect",
"email": "[email protected]"
}
]
}
return body
def handler(event, context):
# get the project name, folder name and item name
project_name = sa_client.get_project_by_id(context['after']['project_id'])['name']
folder_name = sa_client.get_folder_by_id(context['after']['project_id'], context['after']['folder_id'])['name']
item_name = context['after']['name']
# check if the item is from the specific folder or from the root folder
if folder_name == "root":
item_path = project_name
else:
item_path = f"{project_name}/{folder_name}"
# get the annotations of the item
annotations = sa_client.get_annotations(item_path, [item_name])[0]
print("Finished getting annotations")
# check whether there are only tags or mixed annotations
if sum([sum(1 for value in d.values() if value == 'tag') for d in annotations['instances']]) != 0 and sum(
[sum(1 for value in d.values() if value == 'entity') for d in annotations['instances']]) != 0:
annotations_to_be_saved = [value for value in annotations['instances'] if value['tag'] == 'tag']
annotations['instances'] = annotations_to_be_saved
output = "Removed entities"
sa_client.upload_annotations(item_path, [annotations], keep_status=True)
elif sum([sum(1 for value in d.values() if value == 'tag') for d in annotations['instances']]) == 0 and sum(
[sum(1 for value in d.values() if value == 'entity') for d in annotations['instances']]) == 0:
output = "No instances"
annotations['instances'].append(add_comments())
sa_client.upload_annotations(item_path, [annotations], keep_status=True)
sa_client.set_annotation_statuses(item_path, "Returned", [item_name])
else:
output = "Correct instance"
return outputMultimodal Project
Here is an automated script example that receives an event trigger from the platform when the automations are done and the items are marked as Completed. The automated QA script gets the annotations and checks the number of words in the Answer field. If it is less than the given number requirement, the automation adds a comment to the instance and uploads the annotations back to the platform with the changes made.
from superannotate import SAClient
import os
# initialize
sa_token = os.environ.get("SA_TOKEN")
sa_client = SAClient(token=sa_token)
def turn_check(project_name, item_name, folder_name=None):
# get the annotations
annotation = sa_client.get_annotations(f"{project_name}/{folder_name}", items=[item_name])[0]
upload = False
# check the annotations words count of the specific class and skip the comments
for idx, instance in enumerate(annotation['instances']):
if instance['type'] == 'comment':
continue
elif instance['className'] == "Answer":
if len(instance['attributes'][0]['name'].split()) < 400:
upload = True
annotation['metadata']['status'] = "Returned"
annotation['instances'].insert(idx + 1,
{
"type": "comment",
"resolved": False,
"referenceId": f"{instance['id']}",
"correspondence":
[{
"text": "Must have 400 or more words in the Answer",
"email": "[email protected]",
"role": 2
}]
})
# upload the annotations with comments back to the platform and change the status of the item to Returned
if upload:
sa_client.set_annotation_statuses(f"{project_name}/{folder_name}", "Returned", [item_name])
sa_client.upload_annotations(project=f"{project_name}/{folder_name}", annotations=[annotation], keep_status=True)
def handler(event, context):
# get the project name, folder name and item name
project_name = sa.get_project_by_id(context['after']['project_id'])['name']
folder_name = sa.get_folder_by_id(context['after']['project_id'], context['after']['folder_id'])['name']
# check if the item is from the specific folder or from the root folder
if folder_name == "root":
folder_name = ""
item_name = context['after']['name']
# call the function to check the word count
turn_check(project_name, item_name, folder_name)
return TrueClosing Notes
In conclusion, maintaining high data quality is crucial for developing effective models. While automation can greatly simplify the QA process, it is important to recognize its limitations and know when manual checks are necessary. Tools like SuperAnnotate’s Orchestrate feature can enhance dataset validation and quality assurance by saving time and reducing human error. By effectively integrating automation with careful oversight, you can uphold the highest standards of data quality and improve model performance.