
LLM Evaluation: BLEU - ROUGE
In natural language processing (NLP), evaluating the quality of machine-generated text is crucial for assessing and improving models. Two widely recognized metrics for this purpose are BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation). These metrics enable teams to quantify the similarity between machine-generated text (candidates) and human-provided references, offering insights into the performance of various NLP systems.
BLEU Metric
BLEU (Bilingual Evaluation Understudy) is one of the most widely used metrics for evaluating the quality of text generated by machine translation models, as well as other natural language processing (NLP) systems like image captioning and dialogue generation. It works by comparing the generated output (candidate) against one or more reference outputs, measuring how similar the candidate is to the references.
The BLEU score ranges from 0 to 1, where a score closer to 1 indicates a high level of similarity between the candidate and the reference. While BLEU is highly effective, it is important to use it correctly to ensure accurate model evaluation.
ROUGE Metric
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a widely adopted metric for evaluating the quality of text generated by natural language processing (NLP) systems, particularly in tasks like text summarization, paraphrase generation, and machine translation. Unlike BLEU, which focuses on precision, ROUGE primarily emphasizes recall by measuring the overlap between the generated text (candidate) and one or more reference texts.
The ROUGE score typically ranges from 0 to 1, where values closer to 1 indicate a higher degree of similarity between the candidate and the reference. While ROUGE is a robust and interpretable metric, careful implementation and interpretation are critical to ensure its reliability in assessing model performance.
Overview of the score
The comparison in BLEU is based on matching n-grams (continuous sequences of n words) between the candidate and the references.
- N-gram: A sequence of n words. For example, in the sentence “the cat is on the mat”, 1-grams (unigrams) would be words like “the”, “cat”, etc., and 2-grams (bigrams) would be “the cat”, “cat is”, etc.
- Precision: BLEU calculates how many n-grams from the candidate text appear in any of the reference texts.
- Smoothing: This is applied to avoid a score of zero when higher-order n-grams are not found in the references, which is common in shorter sentences.
ROUGE measures the overlap of n-grams, sequences, or units between the candidate text (the model's output) and one or more reference texts (human-provided ground truths). Its focus on recall ensures that the generated text captures as much relevant information from the reference as possible.
- N-gram: A sequence of n words used for comparison. For example, in the sentence "the cat is on the mat," 1-grams (unigrams) would be words like "the," "cat," etc., and 2-grams (bigrams) would be "the cat," "cat is," etc.
- Recall: ROUGE primarily calculates the proportion of n-grams from the reference texts that appear in the candidate text, emphasizing how much of the reference content is captured by the candidate.
- Variants:
- ROUGE-N: Measures n-gram overlap, typically for unigrams (ROUGE-1) and bigrams (ROUGE-2).
- ROUGE-L: Evaluates the longest common subsequence (LCS) between the candidate and reference, capturing sentence-level structure and fluency.
- ROUGE-W: A weighted version of ROUGE-L that accounts for gaps between subsequence matches.
- ROUGE-S: Considers skip-bigrams, or word pairs that appear in the same order but may have gaps in between.
Methodology
BLEU Metric
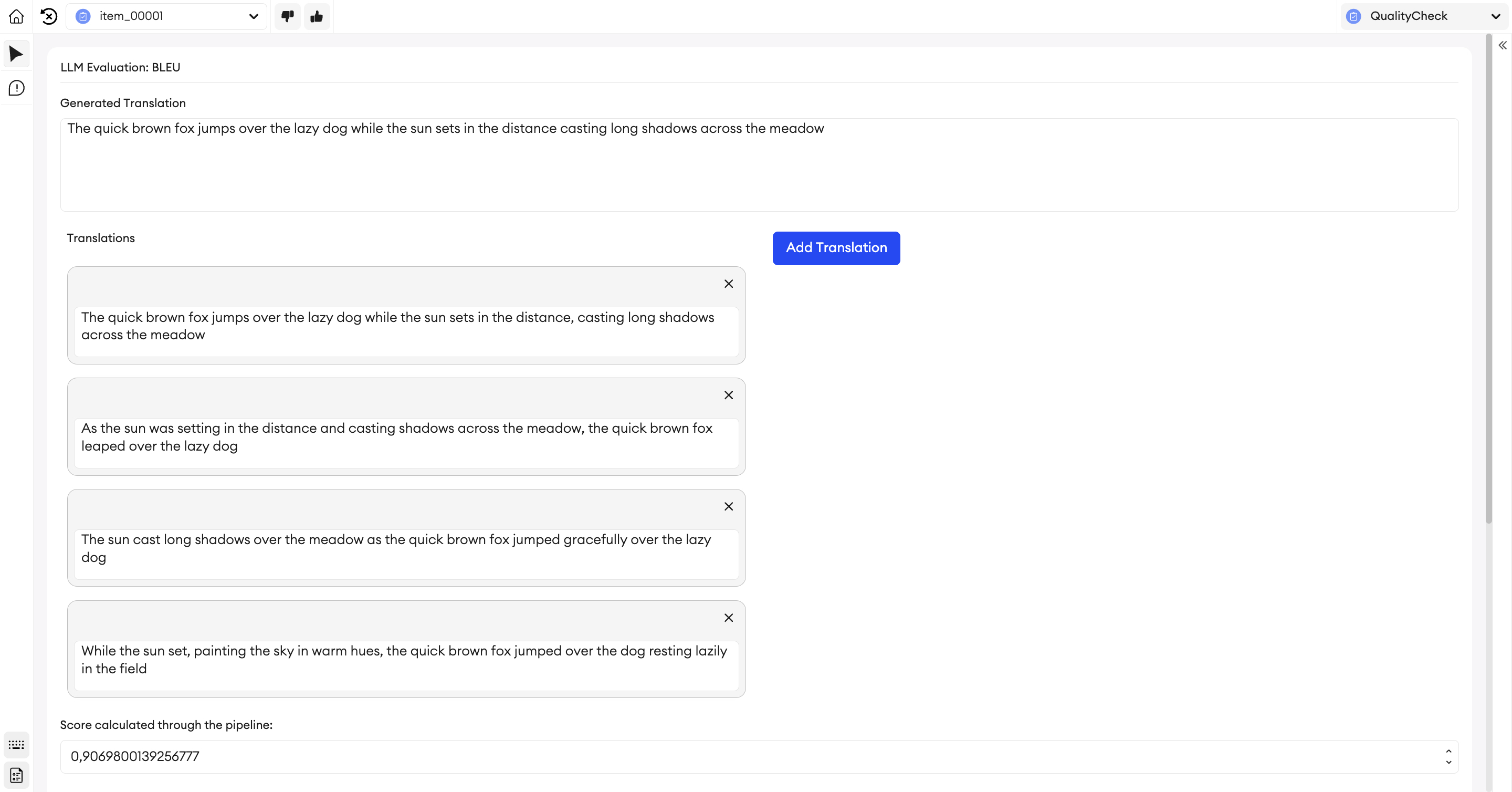
This section explains how BLEU can be used to evaluate NLP models through three distinct examples: machine translation, image captioning, and dialogue systems. Each example will include a step-by-step explanation of the process.
Example: Machine Translation
Goal: To evaluate how closely a machine-generated translation matches human translations.
Approach:
- Reference Translations: Collect multiple human-provided translations for the given source text. Having multiple references helps account for variations in human language.
- Candidate Translation: Obtain the translation generated by the learning model.
- BLEU Calculation:
- Use the
sentence_bleufunction from thenltk.translate.bleu_scoremodule. - Apply a smoothing function, such as
SmoothingFunction().method1, to avoid zero scores in cases where higher-order n-grams are not matched.
- Use the
- Result Interpretation: The output score indicates the similarity between the candidate translation and the reference translations.
ROUGE Metric
This section explains how ROUGE can be used to evaluate NLP models through three distinct examples: text summarization, paraphrase generation, and machine translation. Each example will include a step-by-step explanation of the process.
Example: Text Summarization
Goal: To evaluate how well a machine-generated summary captures the key content of a reference (human-provided) summary.
Approach:
- Reference Summary: Obtain a human-generated summary for the input text. This serves as the ground truth.
- Candidate Summary: Generate a summary using the NLP model being evaluated.
- ROUGE Calculation:
- Use the
rougepackage or other implementations to calculate ROUGE scores. - Focus on different ROUGE variants depending on the evaluation needs:
- ROUGE-1 and ROUGE-2: To measure unigram and bigram overlaps for capturing content fidelity.
- ROUGE-L: To assess the longest common subsequence for structural similarity.
- ROUGE-S: To evaluate skip-bigram matches for non-contiguous word pairs.
- Normalize text by converting to lowercase and removing stop words (optional, based on the setup).
- Use the
- Result Interpretation:
- A higher ROUGE-1 score indicates strong content matching.
- ROUGE-2 and ROUGE-L scores suggest better preservation of phrase and sentence structures.
Using BLEU-ROUGE as a quality metric
The BLEU metric can be effectively applied to automate quality assurance. In annotation tasks, BLEU can measure the similarity between machine-generated annotations and human-provided reference annotations. This can be used to compare human written answers to the “golden set” to automate the annotator’s “quality”. This automation can streamline the QA process by providing a quantifiable score for annotation accuracy, identifying inconsistencies, and reducing the need for manual reviews.
Workflow
This is the workflow of setting up a project to automatically calculate the BLEU score (ROUGE can also be done similarly). The following are the steps you need to follow to create a project, upload items, calculate the score after each annotation, and possibly automate part of the QC process through those metrics.
-
Create the import JSON.
{ "image_url": "<ADD_URL_HERE>", "auto_caption": "The DeLorean Alpha5, featuring its signature gull-wing doors, stands as a modern reinterpretation of the iconic classic." } -
Create the Multimodal Project.
-
Set up the component data with
{{auto_caption}}to import the key's value from the JSON when uploading. Do the same with the Image component's Source URL. If the image is located in a private external storage, make sure CORS is enabled for it, and format the URL's value like so:{{sign(image_url)}}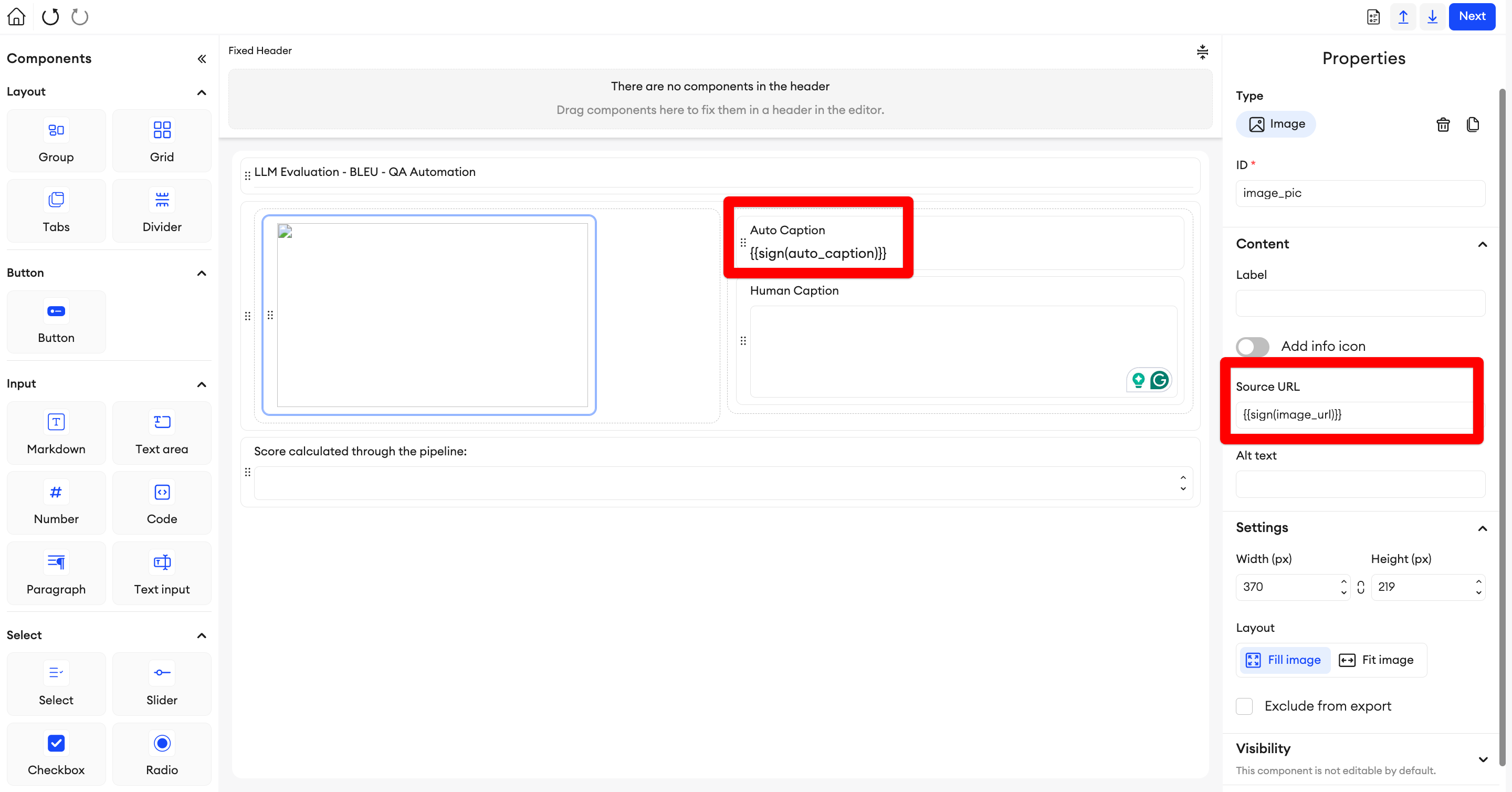
Note that you can also upload the content through CSV.
-
Set an action to calculate the BLEU score.
- For this action, we will need to add the NLTK dependency.
fromnltk.translate.bleu_score import sentence_bleu, SmoothingFunction - We will need to get from the item the candidate and the reference values, split them into an array, and calculate the BLEU score:
bleu_mt = sentence_bleu(reference, candidate, smoothing_function=SmoothingFunction().method1) - Save the value to a component created in the custom form editor and re-upload the annotations to the item (with the calculated score).
The following is a possible action code (SuperAnnotate and NLTK dependencies should be added to the action’s dependency’s list):
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction from superannotate import SAClient import os sa_client = SAClient(os.environ.get('SA_TOKEN')) human_caption_component_name = "add_name_here" auto_caption_component_name = "add_name_here” score_store_component_name = "add_name_here" def handler(event, context): item_name = context['after']['name'] project_name = sa_client.get_project_by_id(context['after']['project_id'])['name'] folder_name = sa_client.get_folder_by_id(context['after']['project_id'], context['after']['folder_id'])['name'] item_path = project_name + "/" + folder_name reference = "" candidate = "" annotations = sa_client.get_annotations(project=item_path, items=[item_name])[0] for i in annotations['instances']: if i['className'] == human_caption_component_name: if len(i['attributes'][0]['name'])!=0: reference = i['attributes'][0]['name'] if i['className'] == auto_caption_component_name: candidate = i['attributes'][0]['name'] reference_split = [reference.split()] candidate_split = candidate.split() bleu_mt = sentence_bleu(reference_split, candidate_split, smoothing_function=SmoothingFunction().method1) print(f"Machine Translation BLEU Score: {bleu_mt:.2f}") for i in range(len(annotations['instances'])): if annotations['instances'][i]['className'] == score_store_component_name: annotations['instances'][i]['attributes'][0]['name']=bleu_mt sa_client.upload_annotations(project=item_path, annotations=[annotations], keep_status=True) - For this action, we will need to add the NLTK dependency.
-
Set an action to calculate the Rouge score.
- For this action, we will need to add the
rouge_scoredependency.
from rouge_score import rouge_scorer - We will need to get from the item the candidate and the reference values, split them into an array, and calculate the ROUGE score:
scorer = rouge_scorer.RougeScorer(['rougeL'], use_stemmer=True)scores = scorer.score(reference, candidate) - Save the value to a component created in the custom form editor and re-upload the annotations to the item (with the calculated score).
- For this action, we will need to add the
-
Set a pipeline for the action.
You can set a pipeline so that whenever an item’s status is changed toQualityCheck(fromInProgressorNotStarted), the created action is triggered.
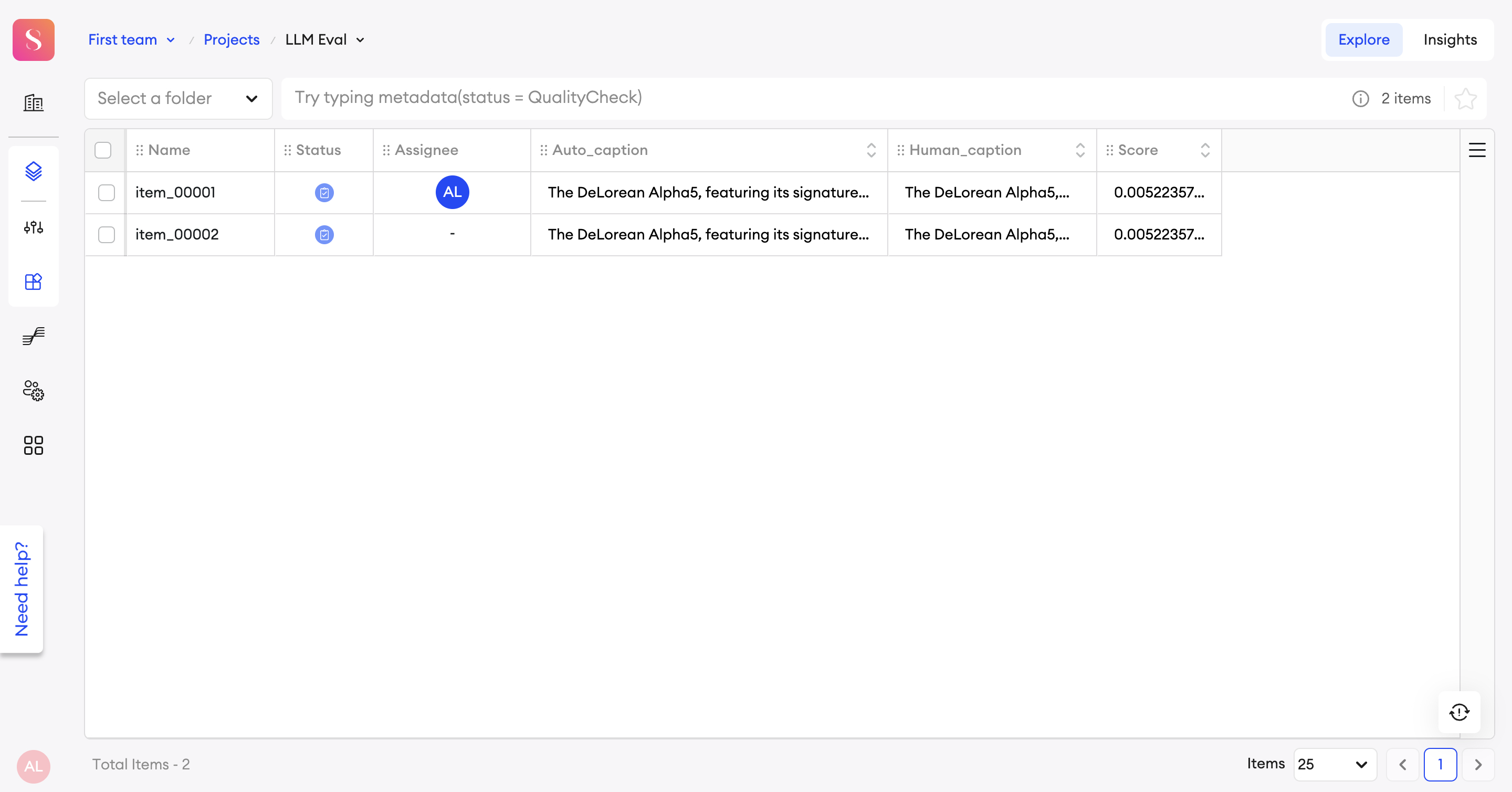
Interaction with the Score:
It is possible to view the scores of multiple items through the explore tab. A BLEU score ranges from 0 to 1, where a score closer to 1 indicates a high level of similarity between the candidate and the reference. Therefore, if the score is smaller than a set constant, the item can be reviewed/automatically returned through the pipeline’s action. Similarly, if the score is higher than a set constant, the item can be accepted/completed automatically by adding automation in the pipeline’s action.
It is also possible to accept/reject items manually through the Explore tab according to the calculated score.
In conclusion
BLEU and ROUGE are indispensable tools in the NLP landscape, serving as benchmarks for evaluating the performance of diverse models, from machine translation and summarization to dialogue systems. The automation of these metrics, as shown in the SuperAnnotate setup, highlights how BLEU and ROUGE can be employed not just for research but also for practical quality assurance tasks. By leveraging pipelines for automatic scoring and quality control, teams can increase productivity and focus on improving the core aspects of their NLP models and annotations. This integration of evaluation metrics with annotation platforms exemplifies how these tools can move beyond theoretical evaluation to directly influence the development and deployment of high-quality NLP systems.
Updated 8 days ago