
Automating data import & export
Streamlining Your Workflow: A Comprehensive Guide to Automating Data Import and Export Processes
Unlock the power of effortless data labeling and fine tuning with SuperAnnotate. Say goodbye to the hassle of manually importing and exporting data. With our platform, you can seamlessly annotate your data, saving valuable time and resources. How? Through our streamlined automation pipelines, which you only have to set up once.

Cloud storage Integrations
The most efficient method of accessing your data within SuperAnnotate involves utilizing cloud storage integrations. You have the ability to establish integrations with various cloud storage providers. SuperAnnotate is granted read-only access to your files, enabling you to create annotations or refine existing ones. This integration requires a one-time setup via the user interface.
Data Synchronization and Re-Syncing
After setting up the integration, you can add data to your project effortlessly, either through our user-friendly interface (UI) or with our SDK functions. If your workflow involves gradually adding data to your storage as a new folder, instead of adding all data at once, you can automate the import process into SuperAnnotate seamlessly through our integration.
Using SuperAnnotate’s Orchestrate feature, you can set up custom pipelines to import data automatically. Whether it's a built-in feature of your cloud storage service or an external automation tool, you can set up a pipeline to automate the import process of your files. This pipeline can be triggered by an Incoming Webhook. This can trigger a custom action to automatically add a new folder to your project, which will contain the latest data in your cloud storage. This is a good solution for you if your data is updated sporadically or spontaneously.
Alternatively, you can opt for setting up a Periodic Event for importing new data. If your data is updated with a predictable frequency, periodic events offer an efficient solution to ensure that your project’s data is regularly kept up to date accordingly.
Both options guarantee real-time updates to your project, eliminating the need for manual intervention. When attaching data from an integrated storage, SuperAnnotate authenticates to your cloud storage and attaches the data to the folder path provided. It will also replicate the folder structure one level down. For example, if we have integrated an AWS S3 bucket as “AWS Integration” and call attach_items_from_integrated_storage with folder_path = “Animals” it will attach all files under that path in the root of the “Animals” project in SuperAnnotate. If there are sub-folders like “Animals/Mammals” which also include files, those will be created in the project and those files will be attached as well. Make sure the files available match the project type you are working with.
To implement either approach:
- Create an Action in Orchestrate using the SDK command to fetch data from your storage.
- Create a Pipeline to automate the process of adding new folders from your bucket to your project.
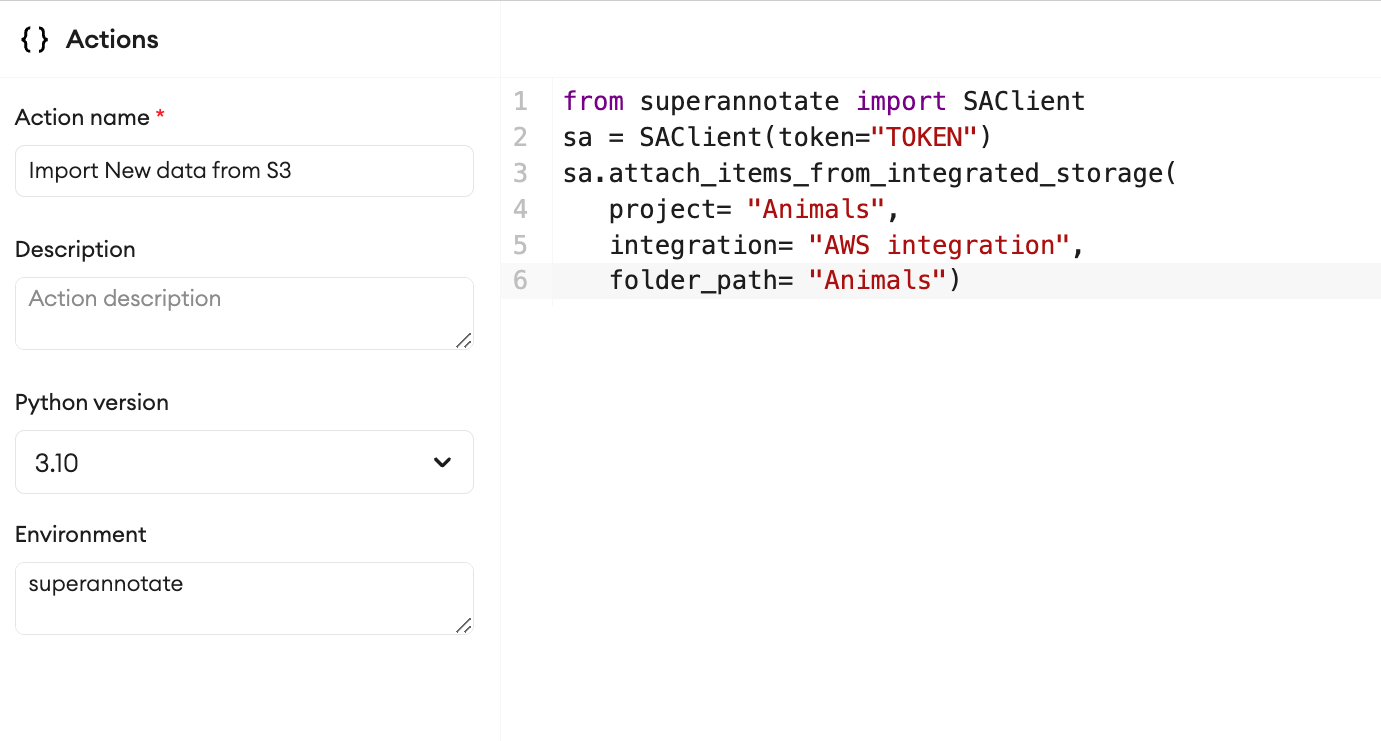
Pipeline for the Incoming Webhook
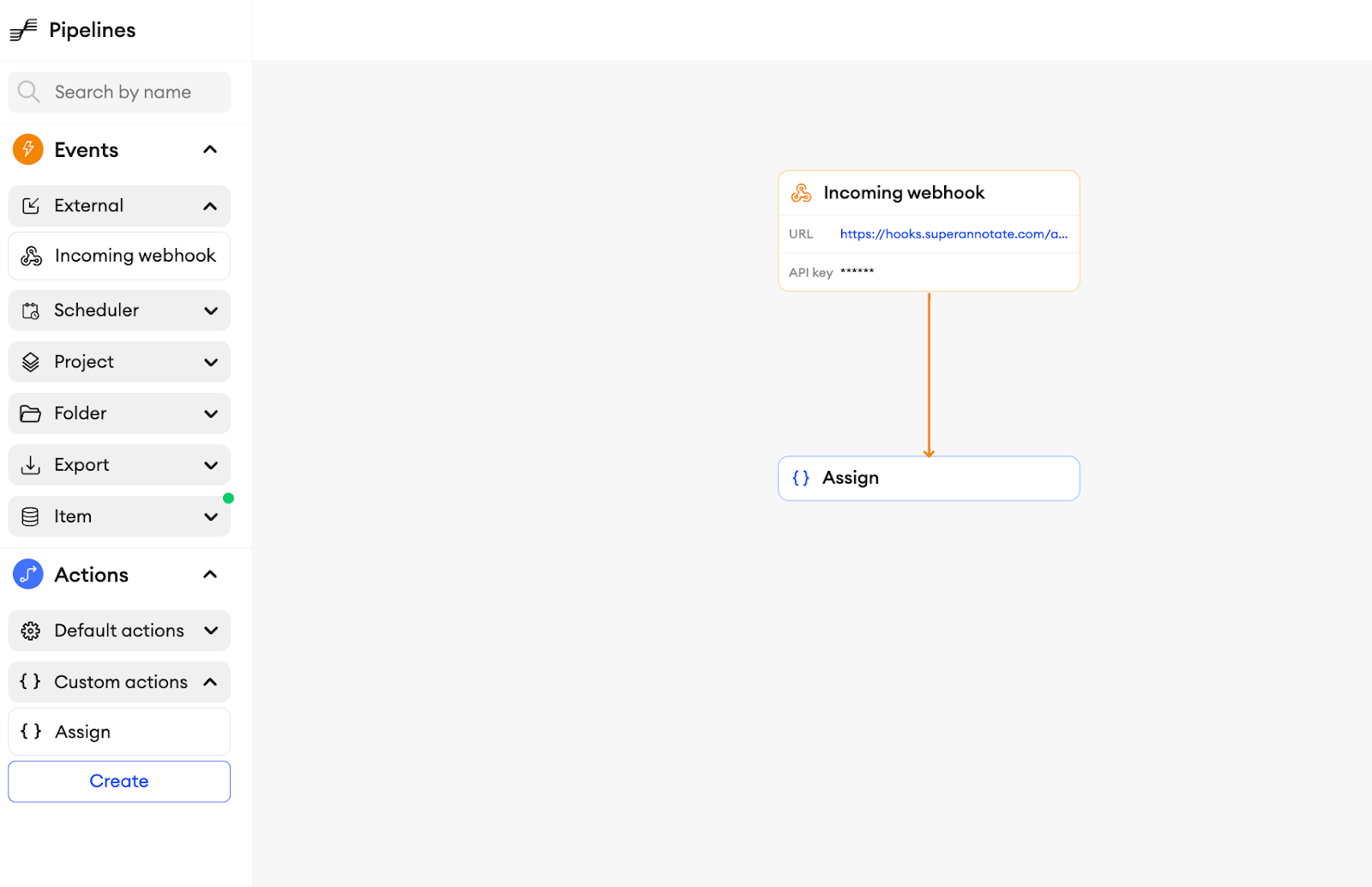
Pipeline for the periodic event
Folder Status Change Notifications
Once you've automated your data import process, take it a step further by setting up a notification system for folder status changes. Receive notifications via email, Slack, or any preferred tool whenever a folder's status is updated. This ensures that the necessary teams are promptly informed about the current status of the annotation process. Whether the data is in the annotation phase, on hold, undergoing quality checks, or completed and ready for model training, the relevant teams—such as the annotation team, experts, or the data science team—will be alerted. This allows for timely review, troubleshooting, and efficient workflow management, ensuring that everyone involved is aware of the progress and can take appropriate action as needed.
Folders within a project can have the following statuses:
- Not Started: Annotation hasn’t commenced within this folder yet. By default, newly created folders are assigned this status.
- In Progress: There is ongoing progress within this folder.
- Completed: All the folder's tasks have been finished.
- On Hold: This indicates that work on the folder is temporarily suspended or halted until further notice.
It is very simple to set up this notification automation in SuperAnnotate:
-
Create an Action for Slack notifications in Orchestrate. We have a ready template for that:
- Create Slackbot
- Add the Slackbot token in the template
- Add the Slack Channel ID in the template
-
Create a Pipeline that tracks folder status updates. You can link as many folders as you want to the same action, if needed.
Exporting Output Upon Project Completion
Once the data is annotated and ready for deployment, automating the export process can streamline workflows. Here are two effective methods tailored to project or folder statuses:
Triggered Pipeline via Project Status:
- When the project is deemed ready for review, the project manager (users possessing Team Admin or Project Admin roles) can mark the project status as Completed.
- Utilize Orchestrate to set up a pipeline triggered by this status change. This pipeline will automatically transfer the prepared data to your designated storage bucket.
We have a template in the Action’s section for adding the annotated JSONs to your AWS S3 bucket(Template name: Store Annotations in AWS S3). This script sets up a connection to AWS based on credentials and stores the annotation JSON file in a specified location. Before running the script, make sure to set the following environment variables:- SA_TOKEN: The SuperAnnotate SDK token. With this key, the client will be automatically initialized.
- EXTERNAL_ID: todo define
- ROLE_ARN: role ARN
- BUCKET_NAME: S3 bucket name
- AWS_ACCESS_KEY_ID: The access key for your AWS account. With this key, the boto3 client will be automatically initialized.
- AWS_SECRET_ACCESS_KEY: The secret key for your AWS account. With this key, the boto3 client will be automatically initialized.
- You can define key-value variables from the Secrets page of the Actions tab in Orchestrate. You can then mount this secret to a custom action in your pipeline.
- For enhanced efficiency, create a pipeline that monitors folder statuses within the project. Once all folders reach a completed status, it triggers the project's completion status update and subsequently exports the data to the designated bucket in the SA Export annotation format or in your preferred format if you add a conversion script in the Action code.
Here is an example script for checking the folder status and changing the project status based on that:
from superannotate import SAClient
sa_client = SAClient("token")
project_name = ""
folders = sa_client.search_folders(project_name, return_metadata=True)
if all(folder["status"] == "Completed" for folder in folders):
print("All folders are completed")
sa_client.set_project_status(project_name, "Completed")
else:
print("Some folders are not completed")This is just an example of an automation strategy for the export process. Various other approaches can be tailored to suit specific project requirements and preferences. Choose the method that aligns best with your workflow and comfort level.
Feel free to adjust the details or add further specifics based on your project's context and requirements!
Updated 10 months ago